几年前写的研究笔记现在回头看感觉全是在抄官方文档里的东西,近期真正在写stream的时候又发现其实根本没算了解,都没自己实现过读流和写流,于是补充一篇。
以下内容主要来自官方文档及自行阅读源码,较多内部逻辑及细节已被省略,只抽象其主干思想:
Readable可读流
- 所有可读流都必须提供
_read()方法的实现,以从基础资源中获取数据。 - 当调用
_read()时,如果资源中已有可用数据,则应该使用this.push(dataChunk)将数据加入到读流的缓冲区队列中,然后_read()应该持续以上操作直到push()返回false。
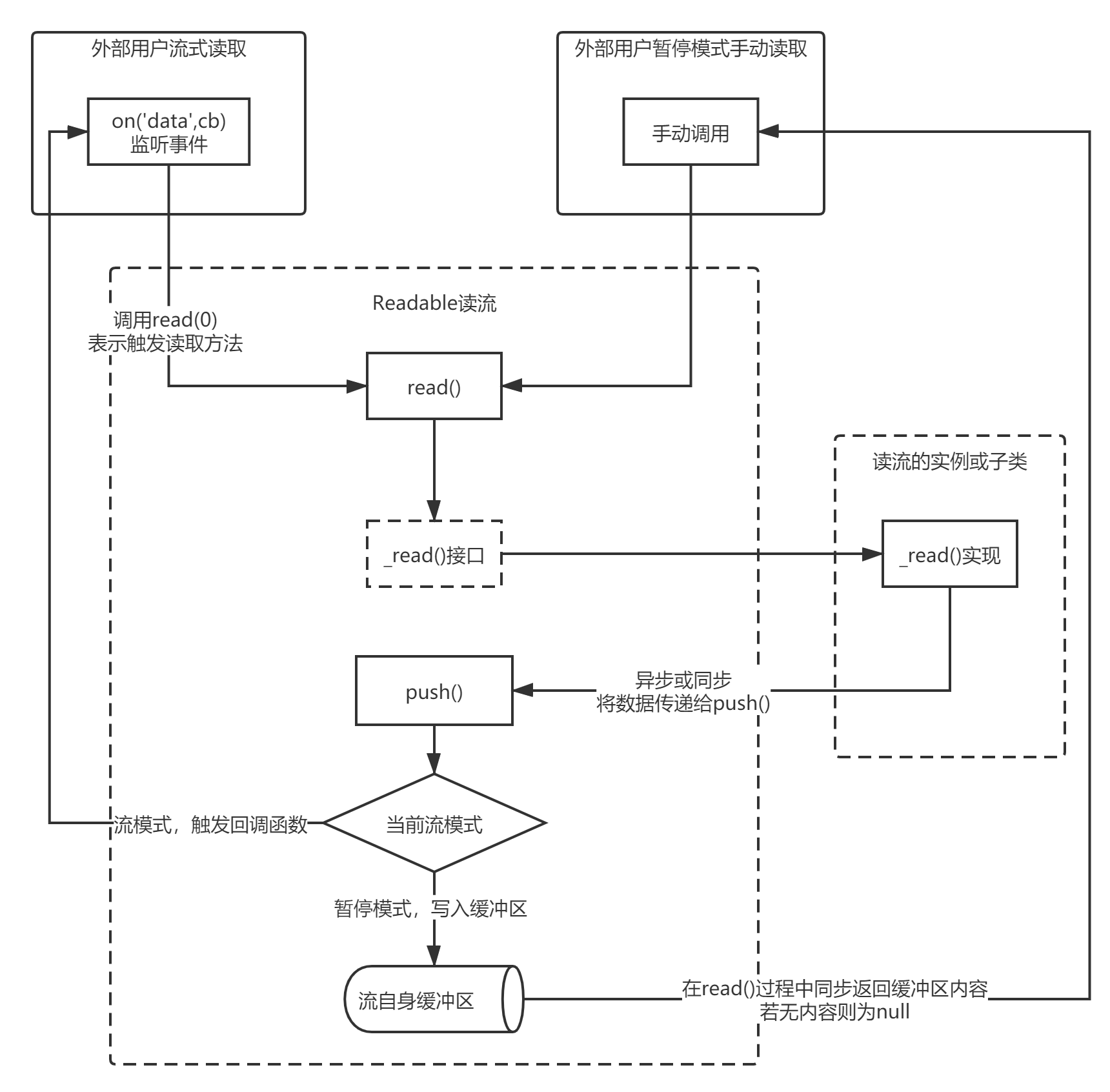
从结论来说,如果你不调用push(),可读流永远不会产生数据。
关于可读流的两种读取模式在这里就不再赘述了,有趣的是可读流内部的缓冲区buffer并不是一个Buffer对象(因为流要支持对象模式,不能只支持二进制数据)或者Array,而是一个自己实现的单链表,带头尾指针,这里应该是考虑方便缓冲区的前后读写,并且不需要使用数组的索引功能。
push()函数还提到说当它返回false时就不应该继续写入了,其实代码内部中只是返回了缓冲区与highWaterMark的大小对比,其实并不会抛弃超过的数据,所以自己实现时多写一些内容进去是没问题的(比如一次批量拿到了N个数据,总不能写一半丢一半)。
Writable可写流
- 所有可写流实现必须提供
_write方法,以将数据发送到基础资源 - 必须调用回调方法来表示本次写入的成功或失败
- 在调用
_write()和回调被调用之间如果有新的write()调用,则这些数据会先被放入缓冲区。调用回调时,流可能会发出“drain事件。
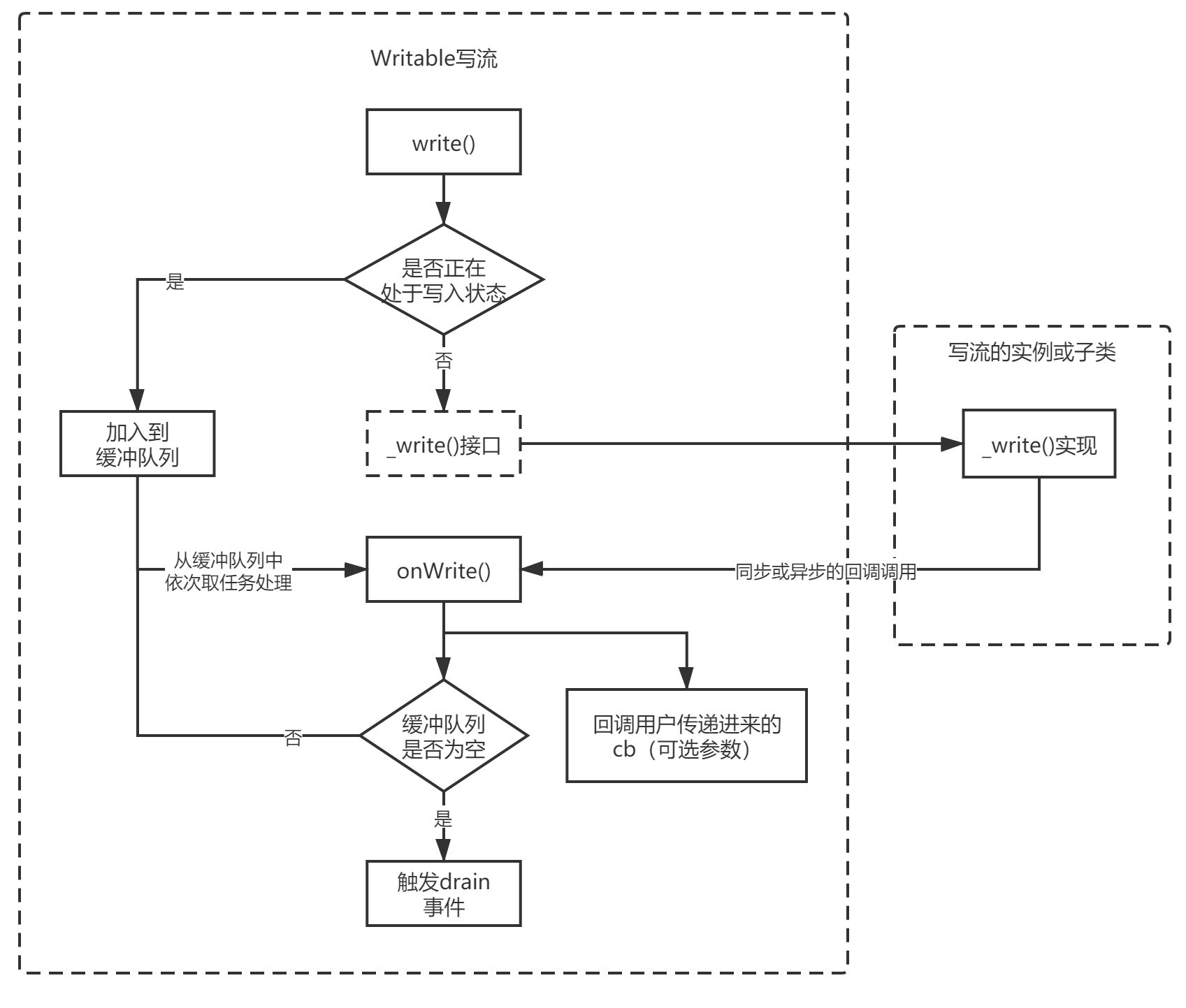
可写流相对比可读流逻辑简单一点,就是包裹一下用户自定义的写方法,并且做缓冲队列,从这里我们能知道很重要的一点:可写流的write()是串行调用的,不支持并发,因此才有了一个writev()方法作为批量写入的替代。write()返回的true/false也仅是表示数据量是否达到了它的水位线,但继续向其写入也是没问题的(当然要注意内存用量)。
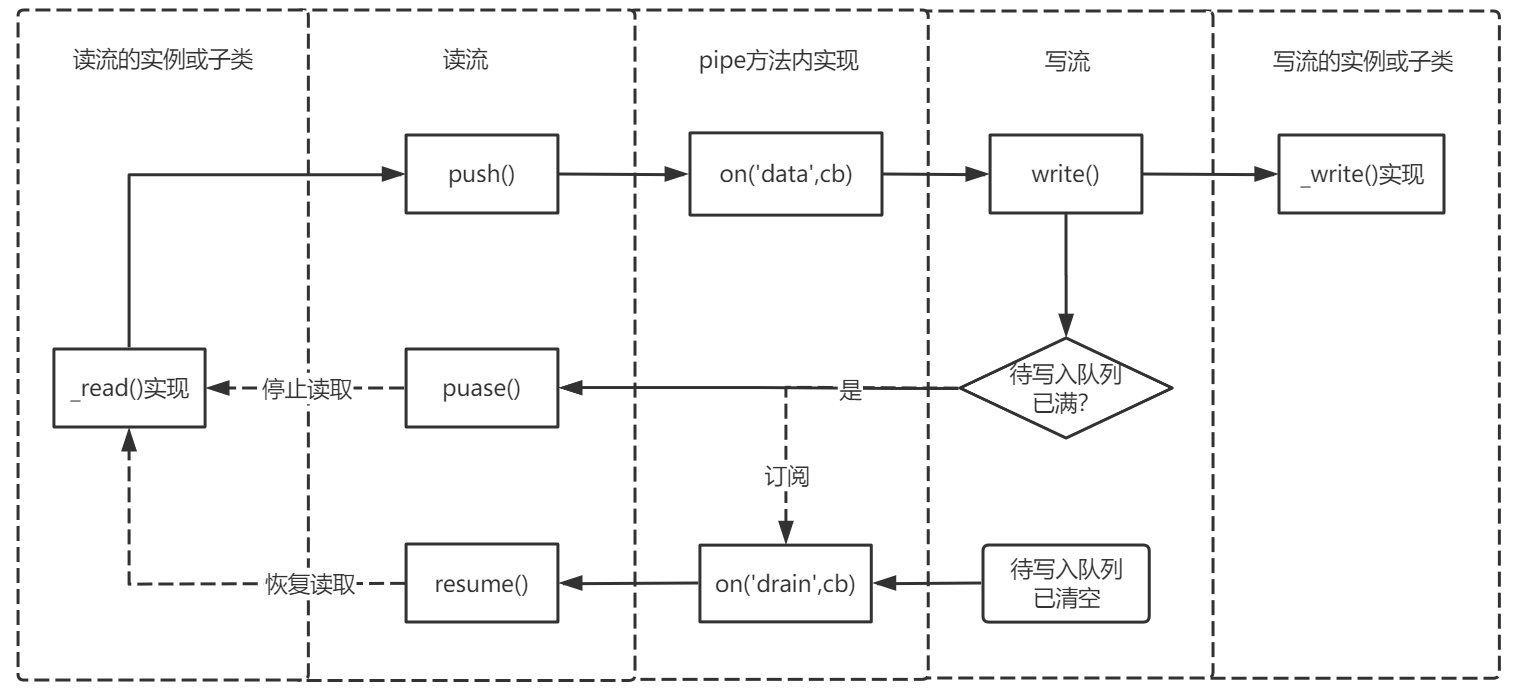
pipe方法
结合上面两张图之后再去看pipe()方法就会比较好理解了
Duplex双工流
就是简单继承了可读流和可写流而已,注意它并不是像一根水管一样一边写了一边就可以读,需要用户自己去实现读写方法,换言之你可以让流入和流出的数据完全无关。双工流与分开实现一个可读流一个可写流的区别,主要在于它可以帮你管理一些流的状态,比如allowHalfOpen不允许半开,这样读流触发end事件(如push(null))时会去关闭写流。不过我们一般需求的场景是反过来的:写流end后就结束读流,但双工流无法实现,因为它没有与你约定好中间的数据流转逻辑,不知道读流何时才能正确被结束,因此我们一般使用它的子类Transform转换流。
Transform转换流
_transform()可以当作是可写流的_write()的用途_flush()是上游流发出end事件时触发的方法,可以在这里将残余的中间数据处理并输出到下游去
转换流是双工流的子类,封装了一些转换的逻辑,主要思路就是:
可写流write()接收数据 => _transform()方法 => push()方法 => 可读流产生数据输出
因为它本质上还是对可读流、可写流的封装,因此类似可写流的highWaterMark与串行写入实现的流速控制、pipe()管道方法等特性都是可以享受的,Node内常见的对流的加密压缩也都是用它实现的,注意的一点是_transform()方法本身是不会帮你把数据push()到可读流的(只有用户自己知道什么时候数据才是可以被输出的),因此要注意自己保留中间数据、及时调用push()输出、以及在_flush()接口内处理残余数据。
这里附一个简单易懂的例子:
1 | const stream = require('stream'); |
刚开始编写流的实现时可能要注意的一点是,流本身带有的那些数据缓冲区、写入队列并不是给你用的,因此如果要你保留一些中间状态,必须要自己建变量存着,比如上面例子的this._chunks。
总结
Node的流设计与Promise一样,本质上都是对回调、异步控制的封装和抽象,由于基于事件订阅的机制实现,它可以实现流速控制,更适合用于持续的异步过程,并可用pipe()管道方法将其简化,在使用中有以下点可以关注:
- 可读流
on('data',cb)形式订阅数据事件的形式,无法直接控制并发量,可以考虑用类似streamQueue这样的形式再做一层控制,或者自己实现一个可写流,使用pipe()来做自动的流速控制 - 可写流的
write()实际是串行处理写入数据,本身虽然保证了数据的有序性,但不一定高效,在追求效率的时候,可以考虑实现_writev()接口,或者不在_write()内等待异步执行,直接回调cb,如果出现问题想要中断流程,可以再手动触发错误ws.emit('error')