背景
近半年接手了一个非web开发类的工作,一直跟数据、数据库和脚本打交道,原项目是windows服bat脚本和.NET命令行程序来跑各种任务的。之前我没有太接触过shell这块,碰到这些bat脚本确实有点把我难到了,各方面相比bash来说还是有很大差距,于是我着手开始做迁移工作
这里推荐一个简单的bash入门教程
而复杂逻辑的exe部分,还是用我熟悉的node.js来重构,在此之前我还没有过命令行的开发经验,算是摸着石头过河
参考资料
开发
链接为全局指令
大多数文档都会提到的一点,在package.json里的bin属性下写好指令名与代码路径后,执行npm link即可全局使用这个指令
注意当前目录
记得代码可能会在任意目录上执行,因此用相对定位来读自己的代码目录内的文件是不可取的,如let s = fs.readFileSync('./a.json')
而应该改成使用__dirname来获取代码目录的绝对路径再去读文件,不过require函数不需要考虑这些,它会自己处理
获取和解析参数
我参考了npm上较为主流的几款命令行模块,看到大多是与具体函数耦合较紧的,需要用代码来配置命令行解析参数,这样的好处是能实现很多高级功能,如默认值、参数验证、自动生成帮助文档等。
而我希望的是每次传不同的子命令时再去动态require代码,并且希望自定义帮助文档,因此只需要一套比较简单的解析库,拿到参数再自己处理,因此暂定使用了yargs
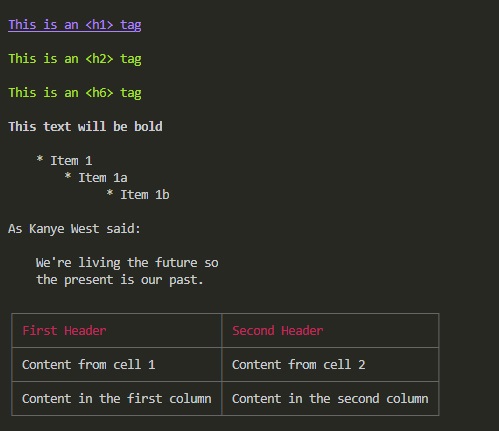
输出markdown文档到控制台
1 | const marked = require('marked'); |
marked-terminal模块将markdown文本转换为带有颜色信息的ANSI格式,然后输出到控制台,赏心悦目
从输入流读入数据
想实现一个标准的UNIX类控制台程序,支持管道是必不可少的,得益于node的封装,我们有很简单的办法来获取输入流的数据
- 从process.stdin流式读取数据,这个时候我之前写的Node对流的Promise包装和并发控制模块就可以派上用场了
- 直接用
fs.readFileSync(0)读取全部内容,0就是标准输入流的文件句柄,当然前提是数据量不大或者需要完整解析的情况(如json),否则我们还是流式处理比较好
调试信息定向到stderr
想保持标准输出,又想在控制台看到调试日志的输出,我们可以将调试的数据都发到stderr去,最终的运行结果才输出到stdout
在常用的日志模块log4js中,只要如此配置就好,这样所有日志输出都不会影响到标准输出流
1 | log4js.configure({ |
注意等待输出流写完成再关闭进程
如果有输出流或者日志文件的情况,要注意不要轻易调用process.exit来主动结束进程,要等待流写入文件完成
1 | //等待流写入完成 |
最好的情况是不写process.exit,只要记得ws.end()结束写入就行,当活动的流(包括标准输出流)全部完成,文件句柄释放后,进程自己会退出
使用更大的内存
node.js使用的v8引擎默认堆内存上限约1.7GB,而在环境变量中加上NODE_OPTIONS=--max-old-space-size=40960后可以扩大可使用的内存大小,当然用大内存不一定是好事,优化代码、精简数据结构、流式处理和避免闭包才是合理做法
使用烘焙/模板函数
在用一些模板或规则批量处理数据的时候,可以考虑使用预构建函数或烘焙模板来优化效率,前端的编译框架对这个就很有研究了,有兴趣可以了解下
对CSV做SQL查询
有些复杂的业务需求需要对文件做数据统计汇总,原先是用lodash的一套函数来处理,但未免还是有些繁复和难以阅读,后来引入了alasql,支持流式地对文件进行sql查询,甚至支持连表语法,我目前也还在初步尝试阶段,有相关需求的可以了解下
总结
得益于现在基本所有前端渲染/JS预编译框架都会用Node的CLI工具来提供服务,npm上会有很多方便的模块供我们使用,在这之上使用Node来开发命令行工具还是很方便快捷的,在shell上如果有复杂的实现需求,不妨试试用Node编写代码来处理
关于控制台程序的一些理解和指导,推荐阅读《UNIX编程艺术》